别那么快抛售英伟达:重新思考AI进化中的算力角色
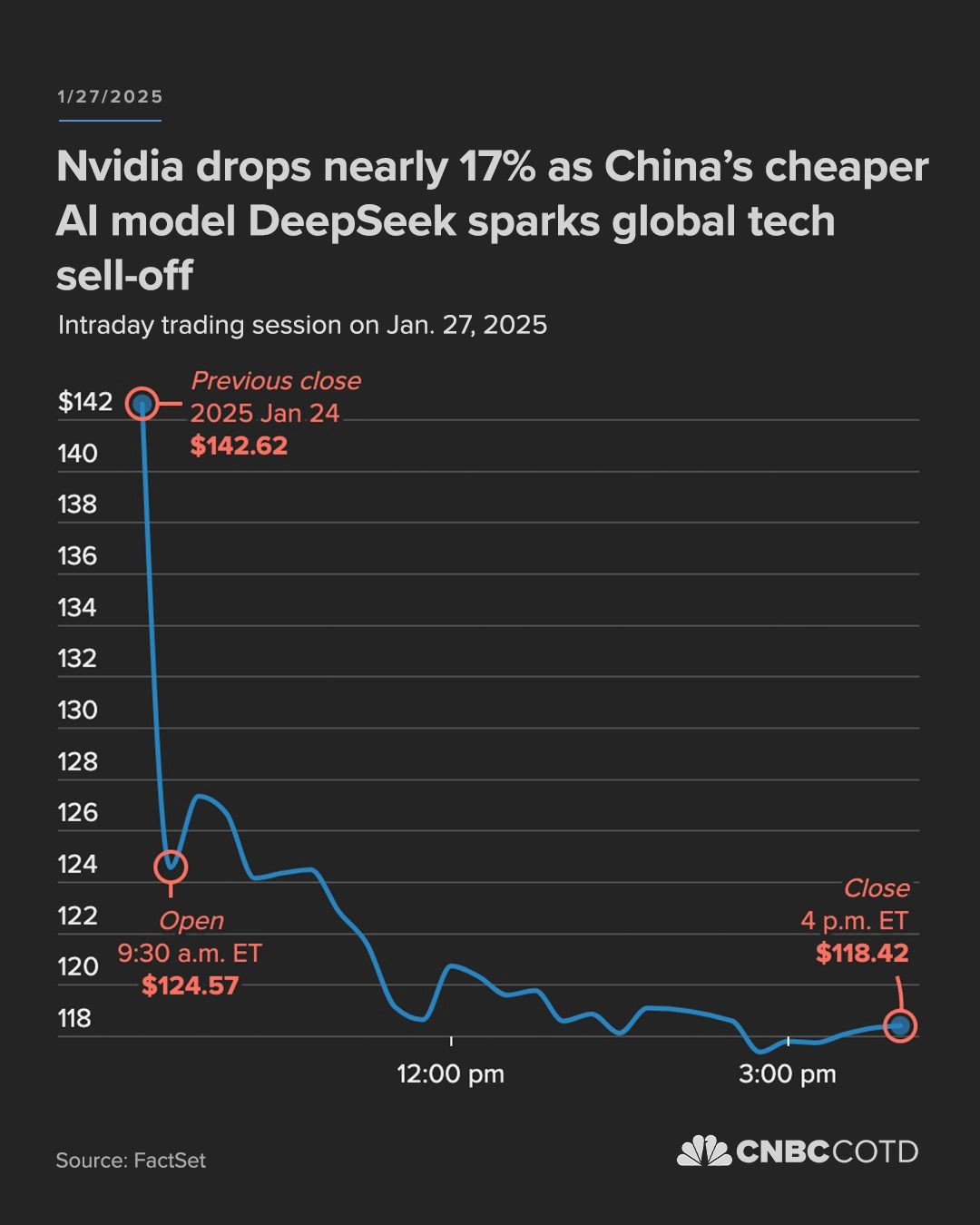
Deepseek新发布的模型引发了AI圈的强烈关注:仅用竞争对手十分之一的GPU算力,就达到了顶级闭源模型的智力水平。这一突破迅速引发媒体广泛报道,在短短24小时内,Deepseek从43个国家应用市场榜首扩展到了160个国家,这家中国AI公司彻底出圈了。华尔街对这一消息反应激烈 - 英伟达股价暴跌17%,市值蒸发近6000亿美金。投资者似乎在传递一个明确信号:科技巨头们不计成本地投入巨资提升算力的策略可能走入了死胡同。
但是,作为一个长期观察AI发展的研究者,我认为这个结论过于简单化了AI进化的复杂性,昨晚也和一些朋友在微信群中做了热烈讨论。今早看到Andrej Karpathy发了一篇关于深度学习与算力关系的推文,感觉他提出的几个观点确实切中了要害,因此再结合一些自己的理解,谈谈为什么市场可能对算力的未来判断过于悲观。